記事Article
【人開SMILE vol.12】ピープルアナリティクス(PA)チームの取り組みと目標
お疲れさまです!
WIL人材開発部 大和田です。
前回の記事 (https://big-smile.willgroup.co.jp/articles/4431.html) では、
PAとは何か、PAチームの発足の経緯、そしてPAチームの取り組みの概要について紹介させていただきました。
今回は、より詳しくPAチームについて知っていただくために、PAチームが行っている分析の具体的な内容と、
今後の取り組みの予定について紹介します!
PAチームが行っている分析の詳細
まずは前回お話しできなかった、PAチームが行っている分析の詳細についてお話しします。
前回、PAの目的はデータを使って人事の様々な意思決定のサポートをすることであるとお話ししました。
一言でデータを使うといっても、例えば各社員の業績につながる数字を可視化する、事業部別に退職者の割合を算出するなどのエクセルでできるようなデータ集計と可視化から、AIを使って活躍者の予測を行うなど専門的な知識を要するものまで、様々な方法があります。
データ分析といった場合それらの全てが含まれるのですが、今回はPAチームが昨年度注力して行っていた、AIによる予測モデルの作成について簡単に紹介します。
AIによる予測モデルの作成は基本的に以下の3ステップからなります。
①活躍者の定義・・・活躍者に対してラベル付けを行う
②AIによる学習・・・AIに活躍者の傾向を学習させる
③予測・・・学習結果を元に、新たなデータについて活躍/非活躍を予測させる

中でも活躍者の定義(ラベル付け)のステップは極めて重要で、どういった社員を活躍者と定義するかはどういった社員が欲しいかに直結するため、よく検討して決める必要があります。
また、ラベル付けの仕方を変えることにより、ハイパフォーマー ・ミドルパフォーマー・ローパフォーマーの3段階に分けた予測や、退職者とその他の社員の違いを学習させて退職者を予測することなども可能になります!
PAチームの目標と今後の取り組み
PAチームは活躍の公式化という目標を掲げています。
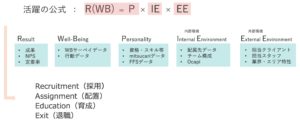
これは簡単にいうと、社員の活躍を様々なデータを使って表し、人事における様々な意思決定に活用しようというものです。
この中で、
・P(個人)・IE(社内環境)データを使った分析
・採用・配置への活用
は2020年度にすでに実装に至っています。
P(個人)データをさらに充実させる、R(業績)データの定義を見直す、効果検証のサイクルを整えるなど課題も見えてきましたが、まずは1年間でAIを活用した人事というものをある程度形にすることができました!
2021年度については、
・EE(社外環境)データの実装・その他データ追加による活躍の公式のさらなる精度向上
・育成・退職抑制などへの活用シーンの拡大
・WB(Well-Being)とR(業績)の関係(連動性)の証明
を目標としています。
簡単に言うと、データをさらに充実させつつ活用シーンもさらに拡大させていき、従業員のWell-Being追求のためのデータ活用をより増やしていくといった内容になります。
EE(社外環境)データという制御しにくいデータを追加することの難しさや、育成のためのデータ分析という新たな取り組みなど、簡単にはいかない問題が多く控えていますが、PAチームでは他社のPA部門にも負けないような高い理想を持って取り組んでいこうと考えています!
おわりに
今回は分析の詳細と、PAチームの目標・今後の取り組みについてお話ししました。
極めて簡単にご紹介したため、説明不足な点も多くあるかもしれません。
今回の記事を読んで興味を持ってくださって、もっと詳しく話を聞きたいと言う方や、データ分析の依頼をしてみたいという方がいらっしゃいましたら、ぜひとも気軽にお問い合わせください。
最後までお読みいただきありがとうございました!